От дисков к SSD
9
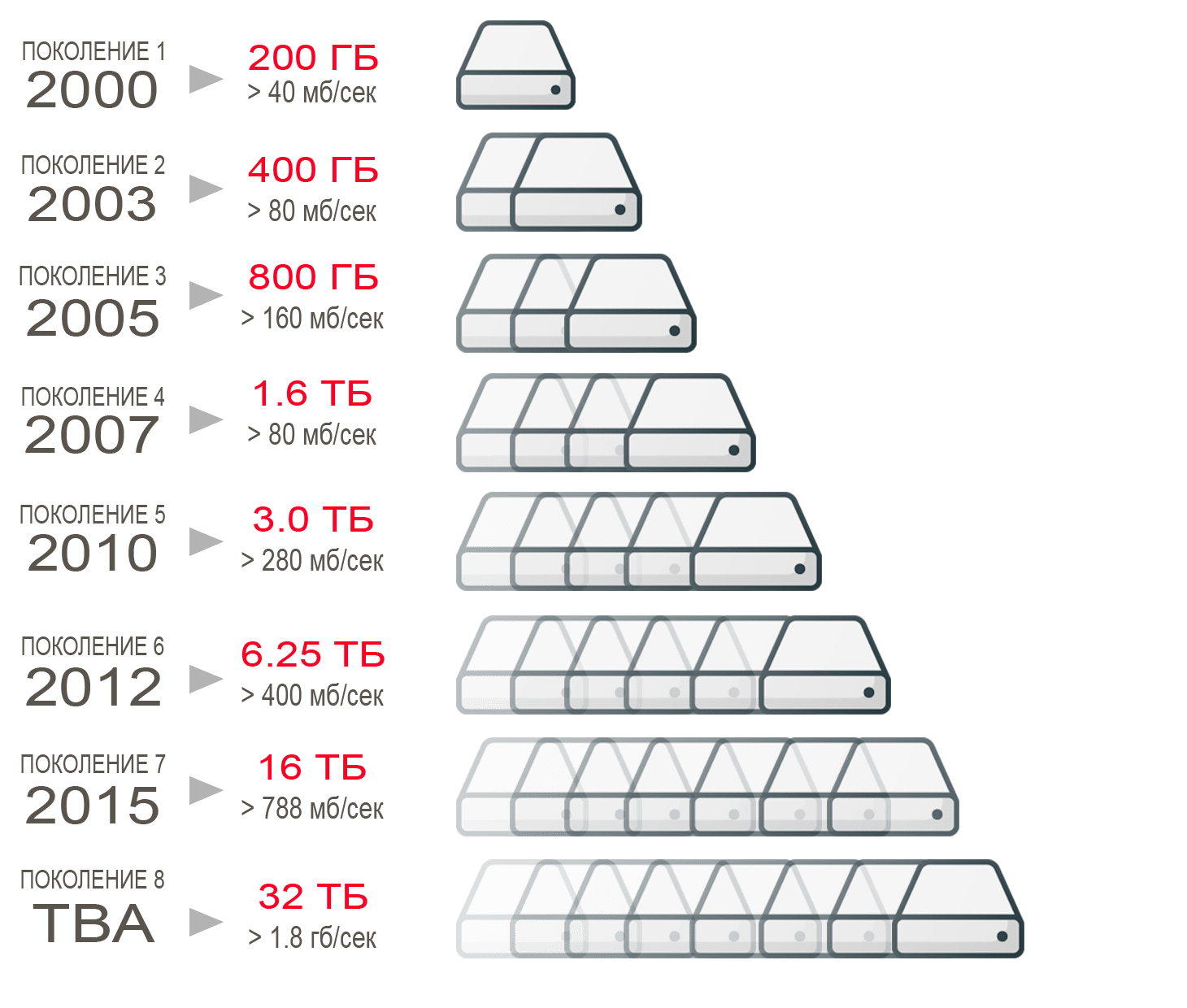
Первые диски, в таком конструктиве, который стал прототипом для современных накопителей, создала шотландская компания Rodime, она выбрала в качестве образца формат популярных тогда 3,5 флоппи-дисков. Выпущенные ею в 1983 году модели RO351 и RO352 имели емкость 6,38 и 12,75 Мб соответственно. По тем временам этот не так мало, оригинальные PC XT комплектовались 5-дюймовыми дисками 5–10 Мб, заметно большими по размеру. В дальнейшем прогресс в области ферримагнитных материалов, способов записи и приводов позволили за 25 лет увеличить емкость дисков в миллион раз. Эволюция механики дисков, материалов и способов записи заслуживает специального рассмотрения.
Однако, как бы ни были высоки показатели емкости и соотношения емкость/цена у самых совершенных HDD, при них остаются их врожденные недостатки – большая задержка как неизбежное следствие механики и последовательные операции чтения и записи, неизбежные при перемещении головки над дорожкой.
Против ожиданий процесс создания быстродействующей электронной твердотельной постоянной памяти (Solid State Device, SSD) проходил медленно: потребовалось более четверти века экспериментов, чтобы лишь в конце 1990-х на рынке появились первые накопители NVM (Non-Volatile Memory). Успешнее других оказались эксперименты с технологией NAND, которую стали называть «флэш». С начала 2000-х она прочно вошла на рынок гаджетов, но только в 2013 году проникла и в корпоративные системы.
Длительность процедуры внедрения NVM обусловлена не столько техническими проблемами, сколько тем обстоятельством, что изначально все современные корпоративные информационные системы создавались именно в расчете на HDD, поэтому сдерживающим фактором стала инерционная масса существующей инсталляционной базы.
Флэш-память является частью более широкой совокупности возможных решений для создания NVM, или «памяти класса хранилища» (Storage-Class Memory, SCM). Помимо флэш-памяти, в эту категорию технологий попадают еще более десятка альтернативных физических методов, среди которых преимущество пока имеют следующие пять: мемристоры (Resistive Random Access Memory, ReRAM); магниторезистивная память с произвольным доступом (Magneto-resistive Random-Access Memory, MRAM); память с изменением фазового состояния (Phase-change memory, PCM); память на доменной стене (Domain-Wall Memory, DWM) и атомная память (Atomic memory). Кроме них, известны еще энергонезависимая статическая память с произвольным доступом (nvSRAM); сегнетоэлектрическая оперативная память (Ferroelectric RAM, FeRAM или FRAM); память на основе механического позиционирования углеродных нанотрубок (Nano-RAM). Из всего этого множества наиболее близки к практическому внедрению ReRAM и PCM.
Область внедрения SCM лежит между памятью и дисками, а поскольку производительность и стоимость технологий, потенциально пригодных для создания SCM, варьируются, то среди решений могут быть более быстрые, близкие по производительности к памяти, и более медленные, сравнимые по производительности с дисками. Сопоставимая по скорости с DRAM память на мемристорах или PCM позволит напрямую подключить к процессору большой объем памяти.
Из нескольких путей самый радикальный и логически простой предполагает подключение карт Solid State Card (SSC) в форм-факторе PCIe по интерфейсу NVMe непосредственно к серверам, хотя это самый логичный и высокоскоростной способ, но он пока применим для ограниченного числа новых приложений. Поэтому широкое распространение получают твердотельные накопители Solid State Drive с той же аббревиатурой SSD, выпускаемые в тех же форм-факторах, что и HDD — 5,25, 3,5, 2,5 и 1,8 дюйма, эмулирующие HDD.
Прямая замена HDD на SSD в существующих СХД вполне допустима, однако она не позволяет в полной мере реализовать потенциал флэш, поэтому остается несколько вариантов создания новых СХД. На данный же момент по экономическим соображениям в количественном отношении будут преобладать гибридные СХД, сочетающие в себе лучшие качества обоих видов накопителей: и HDD, и SSD – их производство растет со скоростью 8–10% в год.
Параллельно, по мере снижения цены флэш-памяти, все большую массовость приобретают массивы All-Flash Arrays (AFA), построенные исключительно на SSD. Этот сегмент рынка пока меньше гибридного, но растет в несколько раз быстрее. И здесь тоже есть свои варианты. Ряд компаний, главным образом стартапы, создают принципиально новые решения класса AFA с нуля (built from the ground up). Те же крупные вендоры, чьи проверенные временем массивы сохраняют потенциал для модернизации, доводят свои существующие продукты путем модернизации ПО и железа до уровня AFA. Они создают системы, которые называют оптимизированными под SSD (flash optimizing storage systems). Можно привести в качестве примера HP с 3PAR StoreServ.
Преимущество массивов AFA, относящихся к категории built from the ground up, по сравнению с optimizing storage systems состоит в том, что их заново написанные операционные системы лучше используют физические возможности флэш, это очевидно и не вызывает возражений. Но не менее очевидно и другое обстоятельство: из-за короткого периода существования built from the ground up им не хватает возможностей тех системных средств для управления данными корпоративного уровня (advanced data management features), которые были разработаны за десятилетия для HDD. Вот почему серьезные унаследованные приложения используют эти наработки, без них преимущества в скорости SSD сводится к нулю. Из сказанного следует, что нельзя в лоб сравнивать описанные выше два типа систем, на данный момент у каждого из них есть свои преимущества и перед пользователем стоит проблема выбора той СХД, которая точнее соответствует его требованиям. Для тех, кому важна в чистом виде скорость работы, больше подходят built from the ground up, если же критичны еще и требования корпоративного уровня, то предпочтительнее optimizing storage systems, сочетающие зрелые программные платформы с высокой надежностью и стабильностью, с более высокой, свойственной AFA скоростью работы.
HDD своих позиций не уступают, в прошлом году компания Western Digital представила HDD объемом 14 Тб по технологии черепичной магнитной записи и гермозоны с гелием, а на подходе технология микроволновой магнитной записи (MAMR), в 2022 году та же WD планирует выпустит диск емкостью 40 Тб, у которого удельная стоимость хранения будет на порядок ниже, чем у SSD.








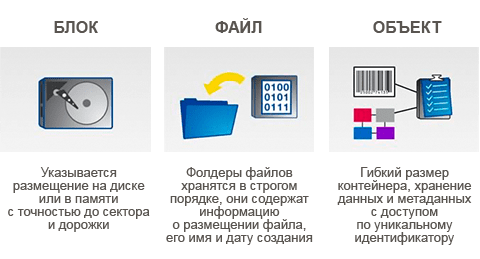
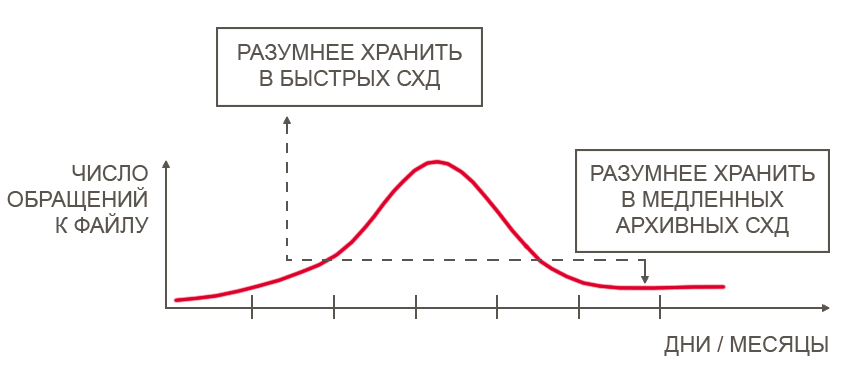
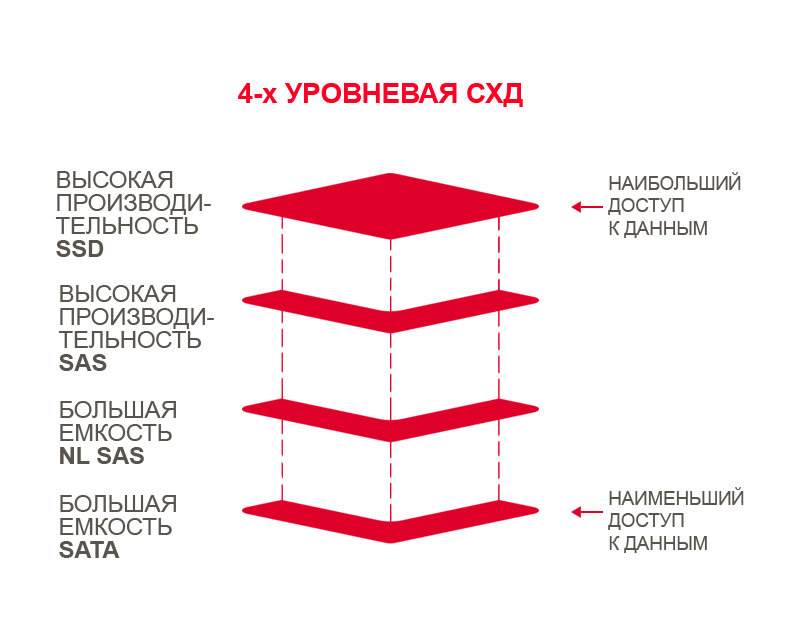
Глазами очевидцев
Алексей Клепиков
вице-президент по ИТ,«Ингосстрах»
Владимир Колганов
руководитель направления «Системы хранения данных», «КРОК»Виктор Ремень
директор по ИТ,«Аэроэкспресс»
Павел Карнаух
руководитель подразделения системных инженеровDell EMC в России, Казахстане и Центральной Азии
Глазами очевидцев
Владимир Колганов
руководитель направления «Системы хранения данных», «КРОК»Виктор Ремень
директор по ИТ,«Аэроэкспресс»
Павел Карнаух
руководитель подразделения системных инженеровDell EMC в России, Казахстане и Центральной Азии
Алексей Клепиков
вице-президент по ИТ, «Ингосстрах»Глазами очевидцев
Виктор Ремень
директор по ИТ,«Аэроэкспресс»
Павел Карнаух
руководитель подразделения системных инженеровDell EMC в России, Казахстане и Центральной Азии
Алексей Клепиков
вице-президент по ИТ,«Ингосстрах»
Владимир Колганов
руководитель направления«Системы хранения данных», «КРОК»
Глазами очевидцев
Павел Карнаух
руководитель подразделения системных инженеровDell EMC в России, Казахстане и Центральной Азии
Алексей Клепиков
вице-президент по ИТ,«Ингосстрах»
Владимир Колганов
руководитель направления «Системы хранения данных», «КРОК»Виктор Ремень
директор по ИТ, «Аэроэкспресс»